
要不这样吧,如果编程语言里有个地方你弄不明白,而正好又有个人用了这个功能,那就开枪把他打死。这比学习新特性要容易些,然后过不了多久,那些活下来的程序员就会开始用 0.9.6 版的 Python,而且他们只需要使用这个版本中易于理解的那一小部分就好了(眨眼)。
—— Tim Peters (传奇的核心开发者,“Python 之禅”作者)
今天我们来聊一聊 Python 的内存管理。
对象引用
变量定义
Python 不像多数的编译语言那样,需要对变量进行显示的声明。变量在第一次赋值时自动声明,变量只有被创建和赋值后才能被使用
1 | k |
动态类型
严格来说变量是没有类型的,对象才有类型,变量引用了什么类型的对象,它就是什么类型。
变量的类型无需声明,是在程序运行时动态确定的。
1 | k = 1 |
对象引用
如何理解变量是对对象的引用呢?内置函数 id() 可以返回对象的内存地址,我们来看一个例子
1 | a = 1 |
给变量 a 赋值 1,又给 b 赋值了 a,此时 b 并没有创建新对象,而是引向了 a 所指向的对象,换句话说 b 是对象的另一个别名。
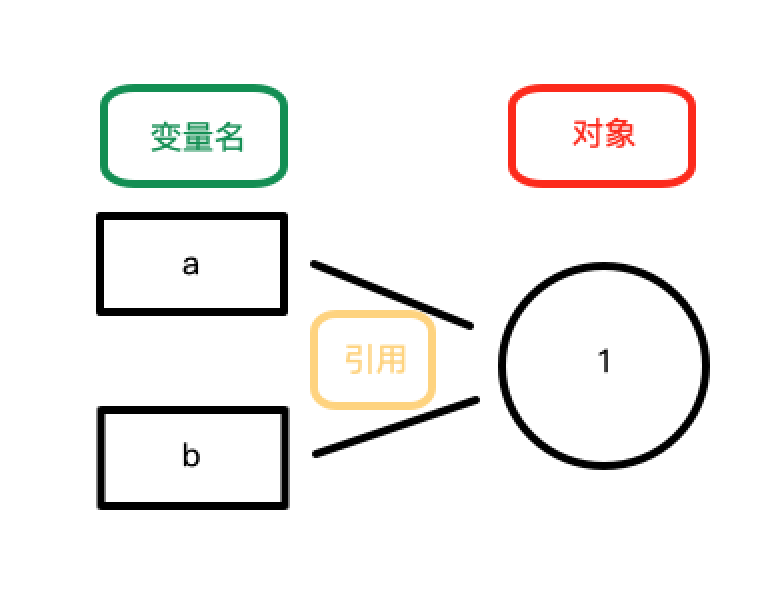
现在考虑一个问题,如果此时将 a 赋值为 2,b 等于多少?
1 | a = 1 |
如果明白了上面说的,可以得到 b 依然等于 1,因为 a 和 b 都作为对象 1 的引用变量,现在只是将 a 引向其他对象,b 并不受影响。
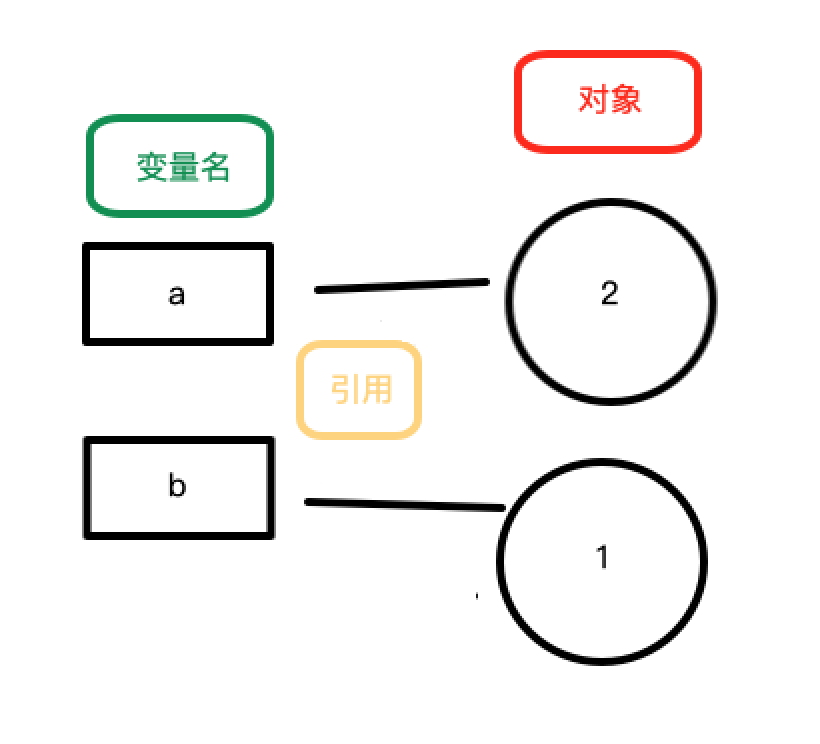
如果这一点可以理解的话,再看一个问题
1 | a = [1, 2, 3] |
这时输出 b 你觉得会返回什么结果呢?
变量 a 和 b 都引用了列表对象 [1, 2, 3],a[0] = 4 只是将列表对象索引位置 0 的子对象替换为 4,变量 a 和 b 对它的引用关系都没有改变,所以 b 也等于 [4, 2, 3]
引用计数
刚才我们讲 b = a 时,提到此时 b 并没有创建新的对象,而是引用了 a 所引用的对象。
每个对象都包含一个头部信息,内容为类型标识符和引用计数器(Reference counter)。当对象被创建时 a = [1, 2, 3] 该对象的引用计数设置为 1,当对象有一个新的引用时,引用计数会自动加 1。
增加引用计数
sys 模块中的 getrefcount() 函数可以获取对象的引用计数。当对象做参数传入该函数时,实际上也创建一个该对象的引用,所以返回值比预期会加 1。
1 | from sys import getrefcount |
对象的引用计数增加,有下面几种情况
- 对象被创建
1 | a = 256 |
114 这个数字有些过于超出我们的预期,我先按下不表,稍后的缓存池小节我会讲到。
- 对象被其他变量引用
1 | b = a |
- 对象成为容器对象的一个元素
1 | l = [123, 256] |
- 对象作为参数传递给函数(新的本地引用)
foo(n)
减少引用计数
有增加,就会有减少。对象的引用不会不休止的增加,下面几种情况引用计数会减少
- 对象的引用变量被赋值给另一个对象时
1 | a = 256 |
- 对象的引用变量被显示的销毁
1 | del b |
del 语句会产生两个结果
- 从现在的变量名称空间中删除
b
- 从现在的变量名称空间中删除
- 对象
256的引用减少 1
- 对象
对象被一个容器对象中移除
1 | l = [123, 256] |
- 容器对象本身被销毁
1 | l = [123, 256] |
- 一个本地引用离开其作用域时,比如
foo(n)函数执行完毕时
当对象的最后一个引用被移除时,该对象的引用计数减少为 0,这会导致该对象无法被访问。该对象就会成为垃圾回收机制的回收对象,而任何对该对象的追踪或调试都将增加它的引用计数,这也将推迟该对象被回收的时间。
缓存池
刚才我抛出了一个问题,对象 256 刚被创建出来,引用计数就是 114,有点诡异。
其实 Python 内部存在一个缓存池,缓存池内的对象在内存中只存在一份。所有符合缓存规则的对象,如果该对象不存在,创建后会进入缓存池,以后再次调用只是增加引用计数,如果该对象已经存在,那么针对它的所有调用都只是增加它的引用计数,即不会增加新的内存地址。这有一个很明显的好处,缓存池中的对象都是程序中最常用到的,缓存池的机制将在一定程度上减少内存的消耗。
现在可以回答刚才的问题了,256 对象身处缓存池中,所以我们以为 a = 256 是对它的创建,但其实只是某一个引用而已。
Python 的缓存池会包含三部分布尔值、小整数和守规矩字符串
布尔值
布尔值比较好说,就两个值,任何情况下它都会被缓存
1 | a = True |
小整数
这个小整数的范围为 [-5, 256],我们想办法对此做一些验证。Python 中判断两个对象的值是否相等时可以使用 ==,而判断两个对象是否为同一内存地址时需要使用 is
1 | a = 256 |
257 超出了整数缓存池的范围,所以每次赋值都会创建一个新对象,即内存地址不同,我们可以通过 id() 函数查看
1 | id(a) |
所以一般情况下你看到的拥有两个相同值的变量,往往他们引向的是两个不同的对象。
守规矩字符串
字符串的缓存逻辑比较复杂,我将符合规则的字符串称为守规矩字符串,规则有下面几种情况
- 长度为 1 时
1 | a = "@" |
- 长度大于 1,并且只含有大小写字母、数字、下划线时
1 | a = "wo_ai_ni_zhongguo" |
某些乘法时
- 乘数为 1
- 字符串长度等于 1
1 | a = "@" * 1 |
- 字符串长度大于 1,且只含有大小写字母、数字、下划线时
1 | a = "wo_ai_ni_zhongguo" * 1 |
- 乘数大于 1,仅含大小写字母,数字,下划线,总长度<=20
1 | a = "wxnacy" * 3 |
面对这么多的规则,完全靠记忆的话,在开发中难免有些畏手畏脚,并且通常我们涉及到的字符串都比较复杂,那么这时我们怎么优化内存的使用呢?
sys 模块中有一个函数 insern(),可以将任何形式的字符驻留在缓存池中,同时也可以将该字符从缓存池中取出
1 | from sys import intern |
每次使用都要调用该函数,才能保持字符串的内存地址一致,刚才我们提到的那些守规矩字符串内部也是这样实现的。我有理由相信,在任何需要字符串复用的地方都可以使用该函数,这将大大的优化程序的内存消耗
相同代码块
你以为到这就完了吗,再等等,还差点。
刚才我们的实验都是在不同代码块中进行的,在 Python 交互模式下,每个独立命令都是一个单独的代码块。而在相同的代码块下,缓存池的规则将简单很多。
任何的整数和布尔类型在相同代码块中都满足缓存机制
1 | def foo(): |
字符串依然要单拎出来说下
- 非乘法得到的字符串都满足缓存机制
1 | def foo(): |
- 乘法时,乘数为 1 时都满足缓存机制
1 | def foo(): |
- 乘数大于 1 时,仅含大小写字母,数字,下划线,且总长度小于等于 20 满足缓存机制
1 | def foo(): |
除了上面说的类型,其它的类型如数组、字典等都不会进入缓存池
1 | a = [1, 2, 3] |
垃圾回收
我们给变量分配的内存,其实是在借用系统资源,有借就要有还。还资源的步骤就是垃圾回收时进行的,Python 解释器将会承担内存分配回收的复杂任务,我们只需要关心我们的业务流程,以及尽量的了解垃圾回收的过程,并写出更好的代码。
引用计数为 0 的
前面我们提到,对象的引用会将它的引用计数加 1,而移除对它的引用会自动减 1。当对象的引用计数为 0 时,它将成为一个待回收的垃圾内存。
垃圾回收器会寻找这些引用计数为 0 的对象,垃圾回收时 Python 无法进行其它的任务,这个过程会将降低工作效率,所以当垃圾内存很少时没有必要频繁的执行垃圾回收。
当Python运行时,会记录其中分配对象(object allocation)和取消分配对象(object deallocation)的次数。当两者的差值高于某个阈值时,垃圾回收才会启动。
查看阈值
1 | import gc |
返回值解释
700垃圾回收启动的阈值10每 10 次 0 代垃圾回收,会配合 1 次 1 代的垃圾回收10每 10 次 1 代垃圾回收,会配合 1 次 2 代的垃圾回收
我们也可以手动启动垃圾回收
1 | gc.collect() |
分代回收
Python 将所有的对象分为 0、1、2 代,所有新建的对象为 0 代,每经历一次垃圾回收,依然存活的对象,会归入下一代对象。
分代(generation)回收策略基于这样的假设,在程序运行过程中,存活时间越久的对象,越不容易在后面的程序中变成垃圾。对于经历了几次垃圾回收依然存活的对象,出于信任和效率的考虑,垃圾回收器会减少对它的扫描频率。
循环引用
相信有过开发经验的同学都会碰见循环引用的情况,两个对象相互引用,会构成引用环(reference cycle)
1 | a = [] |
在引用环中,即使删除了 a 和 b 对象,但是仍然有部分对象,从此以后无法使用,引用计数也不为 0,这将给垃圾回收造成很大的麻烦。
我们来模拟一下这个无法使用、引用计数也不为 0 的对象。
1 | getrefcount("wxnacy") |
相信看过前面章节后,很容易可以理解这个流程。我以短字符串 wxnacy 为参考对象,执行函数 getrefcount("wxnacy") 获取初始引用计数 2 (字符串本身被创建引用一次,getrefcount 函数本地引用一次),容器对象 a 引用加 1,直到 del a 前没有增加引用,而这一步删除容器对象的操作,本应该减少一次对 wxnacy 的引用次数,然后最后再次获取引用次数时,依然为 3,wxnacy 对象就将作为那个无法被使用,但是引用计数又不为 0 的对象遗漏在内存中。
为了回收这样的对象,Python 复制了每个对象的引用计数,记做 gc_ref,假设,每个对象 i,该计数为 gc_ref_i。Python 会遍历所有的对象 i。对于每个对象 i 引用的对象 j,将相应的 gc_ref_j 减 1。
在结束遍历后,gc_ref 不为 0 的对象,和这些对象引用的对象,以及更下游引用的对象,需要被保留。而其它的对象则被垃圾回收。
1 | gc.collect() |
手动执行垃圾回收发现回收了两个对象,这说明这个简单的引用环就有两个无法被回收的对象,实际开发中这样的对象将是一个可怕的数字。
深入了解一门语言,理解内存管理机制是很有必要的。搞清楚内存分配和垃圾回收的过程,将会是提供程序性能的重要一步。现在再回过头来去看以前的代码,就会发现很多有风险的代码隐藏在其中,而现在能写出优秀的代码,也将是理所当然的。
参考文献
- Python 核心编程(第二版)49 页
- Python内存管理机制
- python小数据池,代码块的最详细、深入剖析
- Python深入06 Python的内存管理


