
现在越来越多的网页采用前端渲染页面,这给抓取工作带来了很大的麻烦,通过往常的方法只会拿到一堆 js 方法或者 api 接口,我们当然不想每个网站都去这么费劲的探索他们的 api。
那还有什么好方法嘛,呼叫万能的 Google 爸爸,puppeteer 可以模拟 chrome 打开网页,并可以进行截图、转为 pdf 文件,当然抓取数据也不在话下,因为截图的前提就是它模拟了前端渲染的效果,就像真的打开了网站一样。
这篇文章主要介绍如何通过 puppeteer 进行简单抓取
下载
1 | $ yarn add puppeteer |
使用
首先看一个简单例子,我们依然在不问为什么的前提下,运行一下代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
return {
width: document.documentElement.clientWidth,
height: document.documentElement.clientHeight,
title: document.title
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();
运行后,你会发现它打印出了 document 的宽、高、标题单个属性,现在我们来分析下这段代码都做了些什么。
puppeteer.launch()模拟启动一个浏览器browser.newPage()打开一个新页面page.goto('https://www.instagram.com/nike/')打开某个网址page.evaluate()生成一个沙盒环境来分析 dom,注意在沙盒内console.log()是不生效的browser.close()最后关闭浏览器
分析 selector
在抓取页面时,可以直接借助谷歌浏览器的开发者工具复制 selector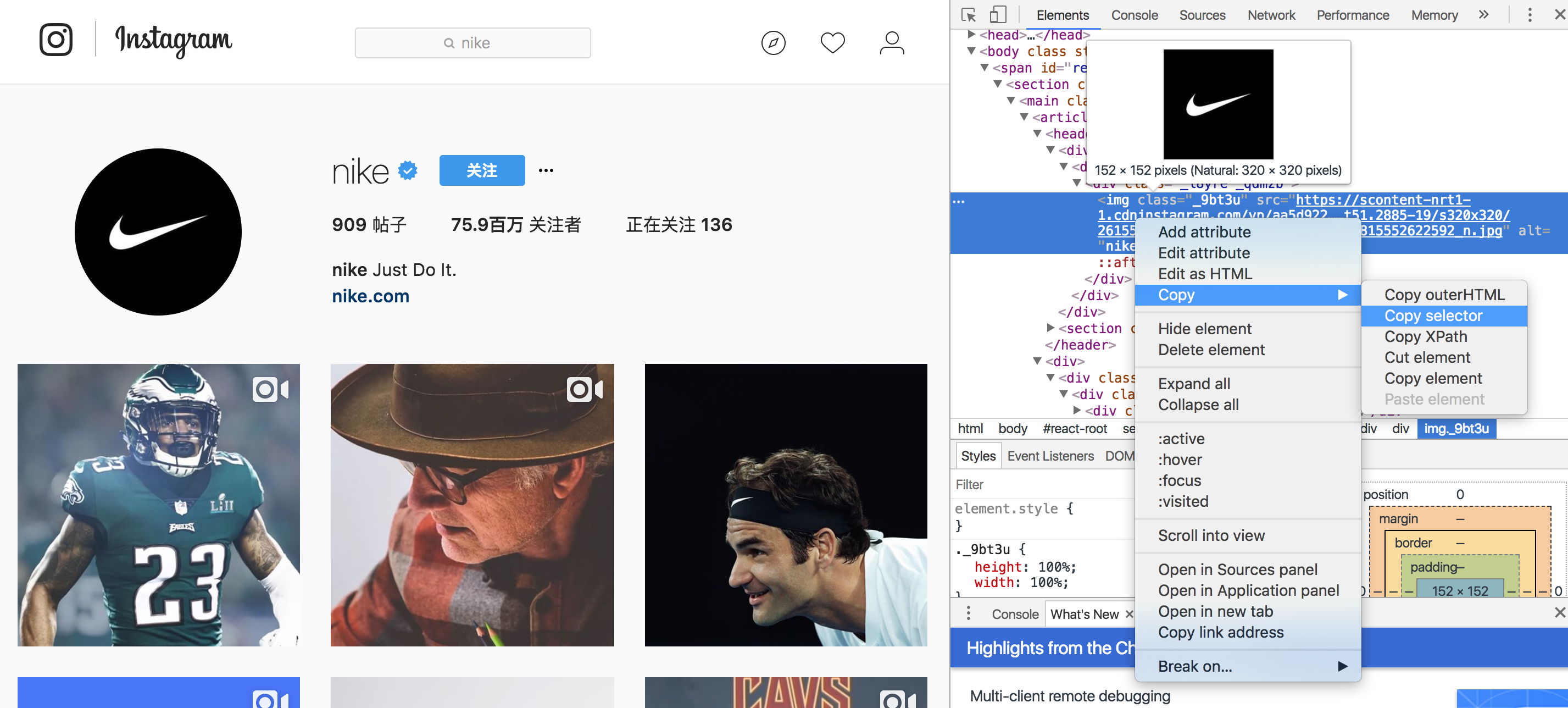
我们想要获取该页面的头像信息,通过开发者工具复制出来的 selector 如下1
#react-root > section > main > article > header > div > div > div > img
这时我们直接使用它既可1
2
3let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
avatar = avatarDom.src
这样我们可以非常方便的分析某个 dom 元素,当然这样的粘贴复制不是万能的,很多时候我们还需要通过分析页面样式来找到更优的解析方式。
完整的使用方式如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.setJavaScriptEnabled(true);
await page.goto('https://www.instagram.com/nike/');
// Get the "viewport" of the page, as reported by the page.
const dimensions = await page.evaluate(() => {
// avatar
let avatarSelector = '#react-root > section > main > article > header > div > div > div > img'
let avatarDom = document.querySelector(avatarSelector)
let avatar = ''
if( avatarDom ){
avatar = avatarDom.src
}
// name
let nameSelector = '#react-root > section > main > article > header > section > div._ienqf > h1'
let nameDom = document.querySelector(nameSelector)
let name = ''
if( nameDom ){
name = nameDom.innerText;
}
return {
avatar: avatar,
name: name,
};
});
console.log('Dimensions:', dimensions);
await browser.close();
})();


